library(tidyverse)
library(caret)
library(neuralnet)11 Neural Network
Note that dataset diamonds actually can be fit by simple models. We proved that in Lasso of Linear Regression is much better since lower MSE/MAE. While the linear regression is overfitted on training set, ridge is lessfitted, Lasso is the best regression on both training set and test set. Please check that.
11.1 neuralnet
data(diamonds)
head(diamonds)# A tibble: 6 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48sum(is.na(diamonds))[1] 0str(diamonds)tibble [53,940 × 10] (S3: tbl_df/tbl/data.frame)
$ carat : num [1:53940] 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num [1:53940] 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num [1:53940] 55 61 65 58 58 57 57 55 61 61 ...
$ price : int [1:53940] 326 326 327 334 335 336 336 337 337 338 ...
$ x : num [1:53940] 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num [1:53940] 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num [1:53940] 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...new_diamonds <- diamonds %>%
predict(dummyVars(price ~ ., data = ., sep = "_", levelsOnly = FALSE), newdata = .) %>%
as.data.frame() %>%
mutate(logprice = log(diamonds$price))set.seed(42)
colnames(new_diamonds) <- gsub("\\^", "_", colnames(new_diamonds))
training.idx <- new_diamonds$logprice %>%
createDataPartition(p = 0.75, list = F)
trainset <- new_diamonds[training.idx, ]
testset <- new_diamonds[-training.idx, ]prepproc <- preProcess(trainset[, -ncol(trainset)], method = c("center", "scale"))
train.x <- predict(prepproc, trainset[,-ncol(trainset)])
test.x <- predict(prepproc, testset[,-ncol(testset)])
trainset.scaled <- data.frame(train.x, logprice = trainset$logprice)
testset.scaled <- data.frame(test.x, logprice = testset$logprice)prepproc <- preProcess(trainset, method = c("center", "scale"))
trainset.scaled <- predict(prepproc, trainset)
testset.scaled <- predict(prepproc, testset)
mu <- prepproc$mean["logprice"]
sigma <- prepproc$std["logprice"]model <- neuralnet(logprice ~ ., data = trainset.scaled, hidden = 0, err.fct = "sse", linear.output = T)
plot(model, rep = 'best')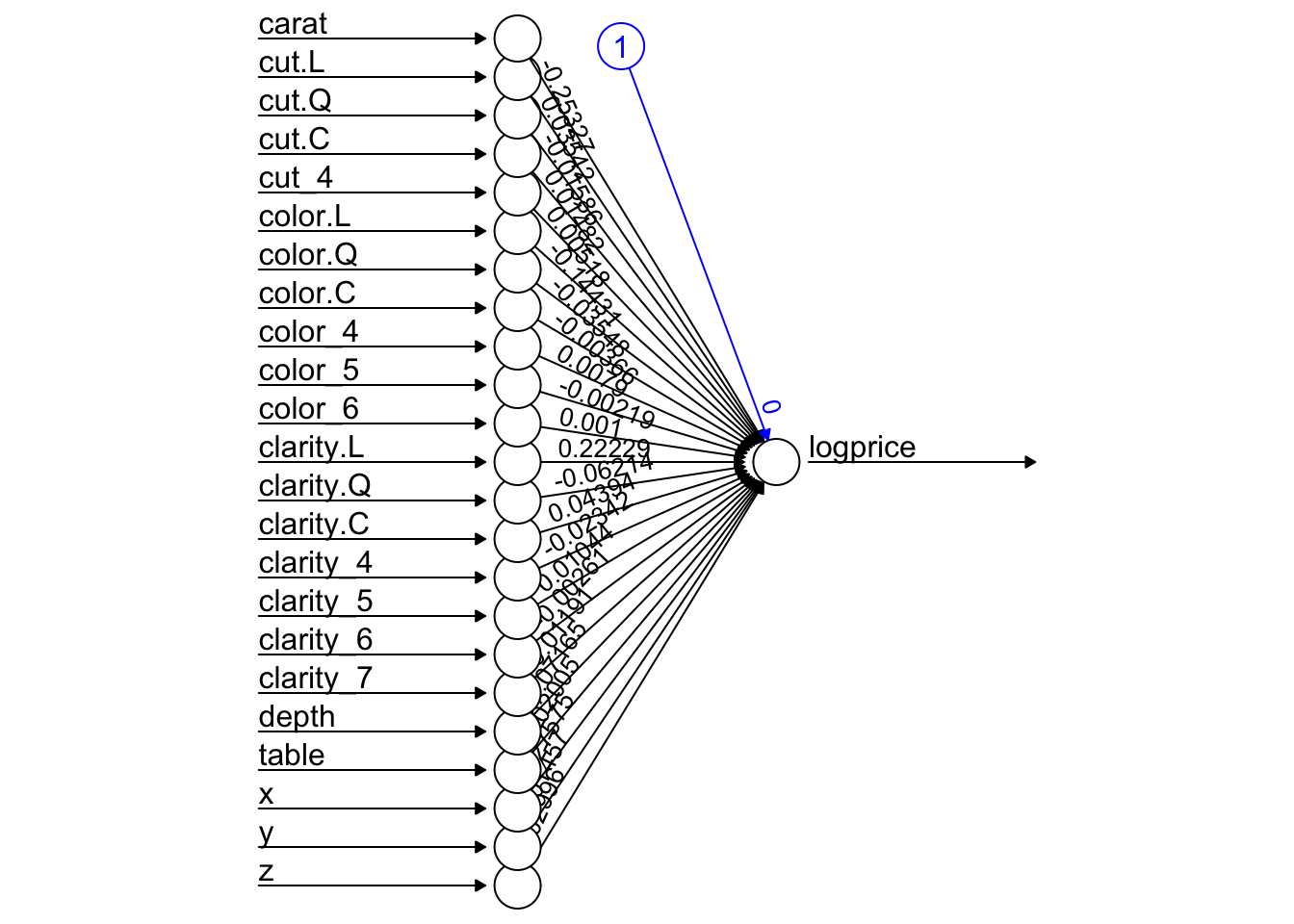
pred_scaled <- compute(model, testset.scaled %>% select(-logprice))$net.result
pred_usd <- exp(pred_scaled * sigma + mu)
performance <- postResample(pred = pred_usd, obs = testset.scaled$logprice)
performance RMSE Rsquared MAE
5848.2315253 0.7159979 3955.0920002 init_weights <- runif(67, min = -1, max = 1)
model_w <- neuralnet(logprice~., data = trainset.scaled, hidden = 3, err.fct = "sse", linear.output = T, startweights = init_weights)
plot(model_w, rep = "best")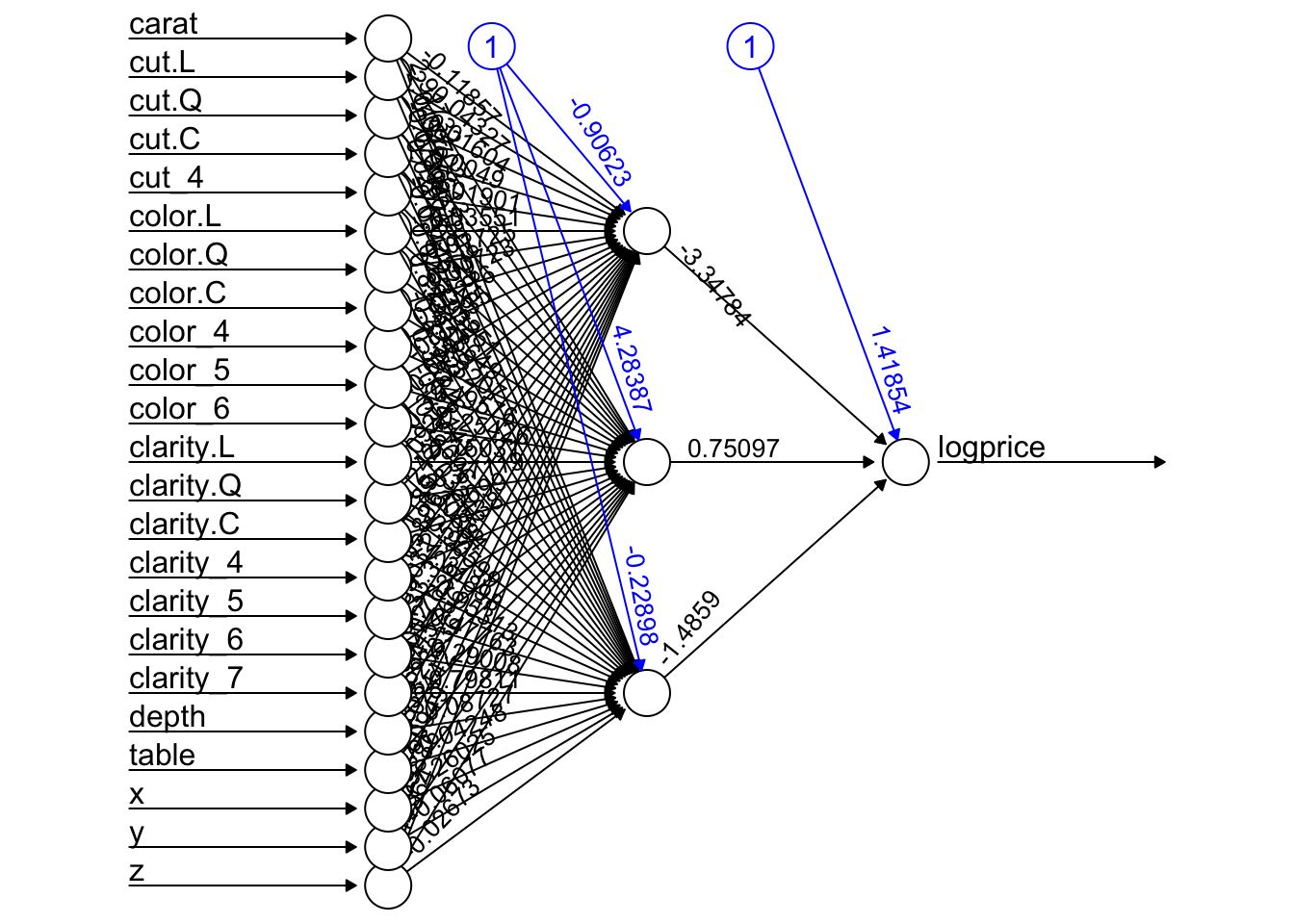
pred_w_scaled <- compute(model_w, testset.scaled %>% select(-logprice))$net.result
pred_w_usd <- exp(pred_w_scaled * sigma + mu)
performance_w <- postResample(pred = pred_w_usd, obs = testset.scaled$logprice)
performance_w RMSE Rsquared MAE
5551.4706951 0.7914741 3906.2047833 rbind(performance, performance_w) RMSE Rsquared MAE
performance 5848.232 0.7159979 3955.092
performance_w 5551.471 0.7914741 3906.205